Wir basteln uns einen RSS-Feed
Programmieren Python RSS WebEs kommt immer mal wieder vor, dass eine Seite, auf der regelmäßige Infos veröffentlicht werden, über keinen RSS-Feed verfügt. Das kann viele Gründe haben, manchmal sind die Wege des eingesetzten CMS einfach unergründlich.
Kann es sein, dass @Bitkom keinen RSS-Feed mehr für Presseinformationen hat? / cc @Bitkom_Health #warum
– Martin Schleicher (@gesundheitswirt) October 31, 2015
Man kann sich aber von fast jeder Seite zum Glück selbst einen RSS-Feed basteln - mit etwas Python, mehr braucht es dazu nicht. (Erwähnte ich schon einmal dass ich der Meinung bin, dass jeder Programmieren können sollte, um solche Probleme für den Hausgebrauch zu lösen?).
Das dauert keine Stunde - und wenn man es hier nachliest vielleicht auch nur 20 Minuten.
Analyse der Zielseite für den RSS-Feed
Der wichtigste Punkt ist herauszufinden. wie die Daten auf der Seite, die einen interessiert - etwa bei dem Bitkom-Pressemitteilungen - aussehen. Dazu öffnet man die Seite und schaut sich den Quelltext im Browser an. Da findet man dann dieses hier:
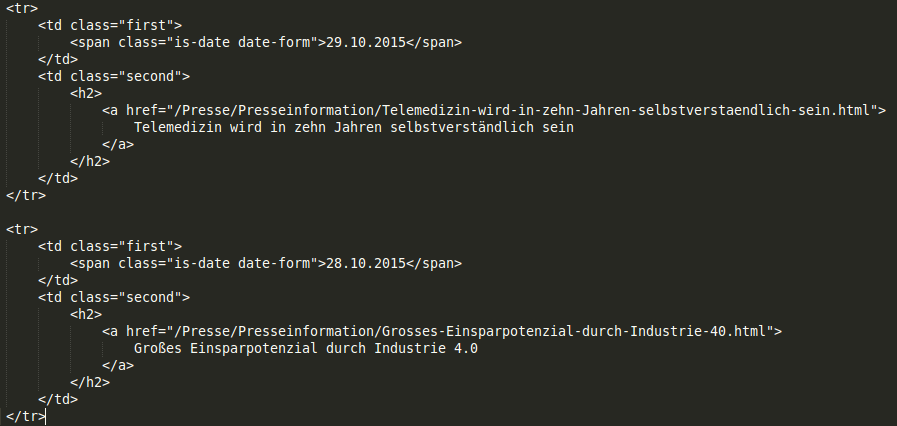
Daraus kann man sehen, dass jede Pressemitteilung in einer Tabellenzeile (tr) steckt, das Datum in einer Tabellenspalte (td) der Klasse “first”, der Titel in einer weiteren Spalte (td) der Klasse “second”. Und schon haben wir alles, um die Liste der Presseinfos von der Website auszulesen und dann mit einem kleinen Modul PyRSS2Gen daraus einen RSS-Feed zu bauen.
Auslesen der Zielseite
Das sieht dann so aus:
def fetchWWW():
ergebnis=[]
url="https://www.bitkom.org/Presse/Presseinformation/index.jsp"
hdr = {'User-Agent': 'Mozilla/5.0 (X11; U; Linux i686 (x86_64); en-US; rv:1.8.1.4) Gecko/20070515 Firefox/2.0.0.4'}
req = urllib2.Request(url,headers=hdr)
try:
page = urllib2.urlopen(req)
except:
debug(" ### ERROR ### Kann URL nicht finden.")
return
html = BeautifulSoup(page)
for zeile in html.find_all("tr"):
eintrag={}
if zeile.find("td",{'class':"first"}):
eintrag['datum']=zeile.find("span",{'class':"is-date date-form"}).get_text()
if zeile.find("td",{'class':"second"}):
info=zeile.find("h2")
eintrag['link']="https://www.bitkom.org"+info.find("a").get("href")
eintrag['text']=info.find("a").get_text().strip()
ergebnis.append(eintrag)
return ergebnis
Wir schreiben einen RSS-Feed
Jetzt müssen wir nur noch diese kleine Routine aufrufen und aus dem Ergebnis unseren RSS-Feed erzeugen:
from bs4 import BeautifulSoup
import datetime
import urllib2
import PyRSS2Gen
def fetchWWW():
...
ergebnisliste=fetchWWW()
items=[]
for ergebnis in ergebnisliste:
items.append(PyRSS2Gen.RSSItem(
title=ergebnis['text'],
link=ergebnis['link'],
guid = PyRSS2Gen.Guid(ergebnis['link']),
description=ergebnis['text'],
pubDate=datetime.datetime.strptime(ergebnis['datum'], '%d.%m.%Y')))
rss = PyRSS2Gen.RSS2(
title = "Bitkom Presseinfos",
link = "https://www.bitkom.org/Presse/Presseinformation/index.jsp",
description = "Aktuelle Pressemitteilungen des Bitkom",
lastBuildDate = datetime.datetime.now(),
items=items
)
rss.write_xml(open("bitkom_presse_rss.xml", "w"))
Fazit
Wenn dieses Skript jetzt z.B. jede Stunde aufgerufen wird, dann wird regelmäßig ein neuer RSS-Feed für die Bitkom-Presseinfos erzeugt. Den Feed kann man in seinem bevorzugten Feed-Reader abonnieren (meiner ist bekanntermaßen ja Fever) oder sonstwas damit tun, z.B. mit Hilfe von IFTTT weiter verarbeiten.
Man könnte jetzt noch die jeweilige Presseinfo auslesen und den Volltext als description mitliefern, nicht nur den Titel der Presseinfo, auch das geht mit Hilfe von BeautifulSoup recht einfach.
Eine Testversion des RSS-Feeds (die sich aber nicht weiter aktualisiert) findet sich hier.